植物鉴别一直是笔者想培养的业余爱好, 机器学习和计算机视觉又是笔者的专业领域, 又由于市面上的植物识别产品做批量化识别要收费; 各产品能识别的植物类别虽多, 但总有一些遗漏, 扩展性不可控. 于是萌生了做 基于图像的植物识别 开源项目的想法.
项目概况
- 模型开源, 项目示例代码依赖少.
- 模型大小为 29.5M, Top1 准确率 0.848, Top5 准确率 0.959.
- 支持 4066 个植物分类单元 (其可能是属, 种, 亚种, 变种等), 且持续增加 (下文可见更新记录).
- 植物名称参考自 iPlant, 包括学名和中文正式名.
项目主页
GitHub: quarrying-plant-id
如果你觉得有用, 欢迎 Try, Star, PR 和 Fork.
也可以在我的个人网站 quarryman.cn 上体验植物识别的效果, 下面是示例:
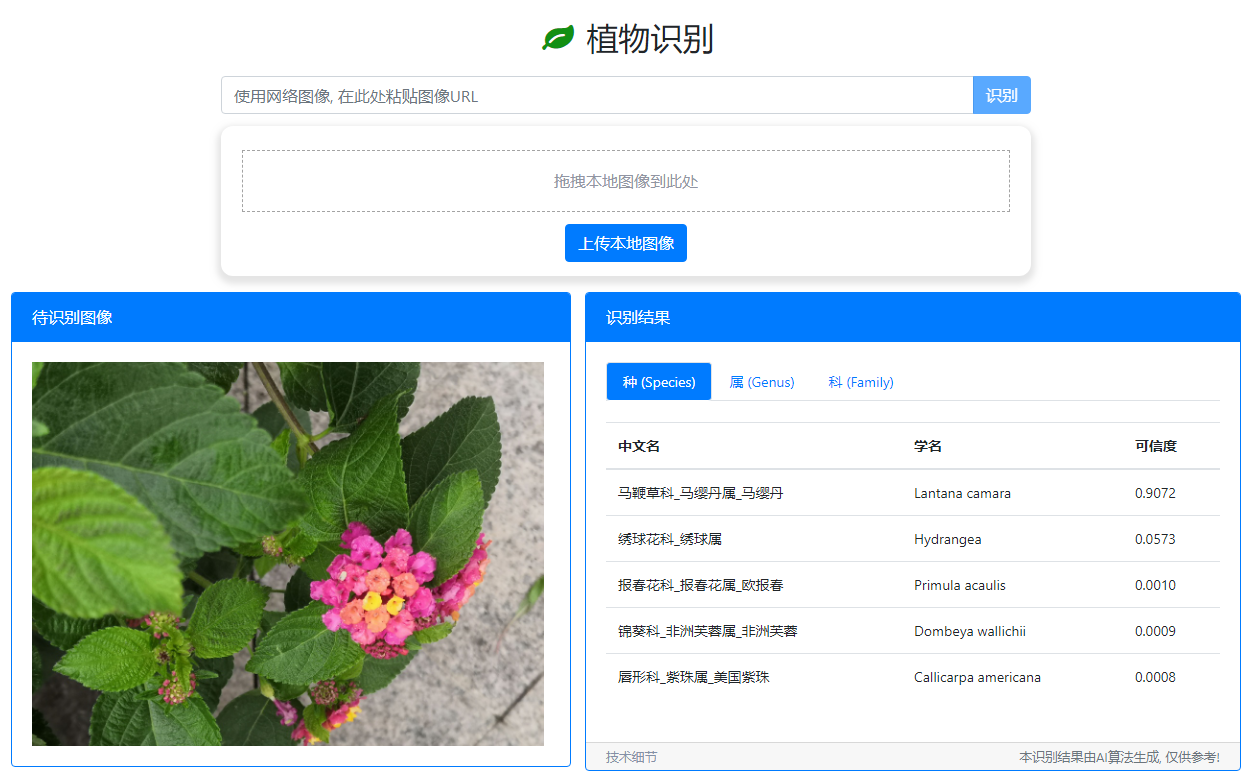
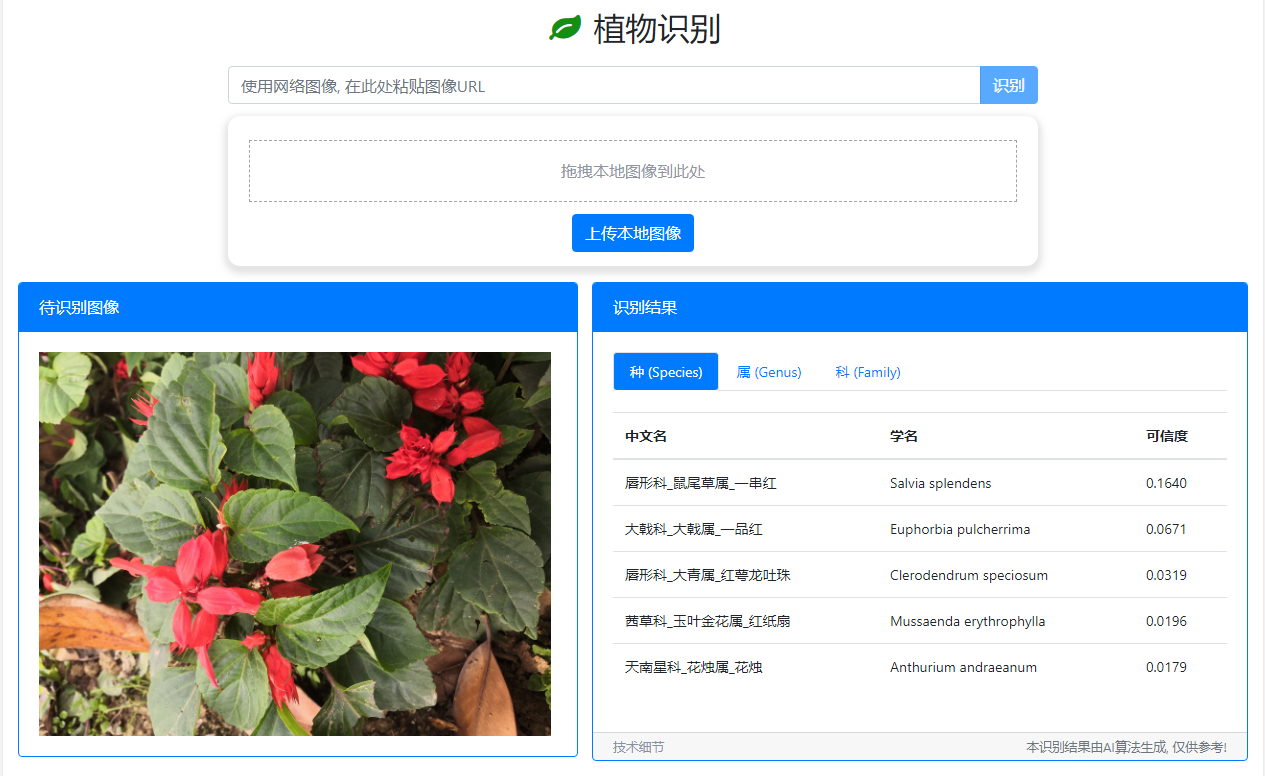
一些细节
数据收集和整理
数据是深度学习的基石, 笔者花了大量的时间在数据收集和整理上.
数据的主要来源有: 百度图片, 必应图片, 新浪微博, 百度贴吧, 新浪博客和一些专业的植物网站等. 除了新浪微博, 其他都用了爬虫. 另外还有一些数据是笔者自己拍摄的.
爬虫爬取的图像的质量参差不齐, 标签可能有误, 且存在重复文件, 因此必须清洗. 笔者尝试的清洗方法包括自动化清洗, 半自动化清洗和手工清洗.
自动化清洗包括:
- 滤除小尺寸图像.
- 滤除宽高比很大或很小的图像.
- 滤除灰度图像.
- 图像去重: 根据图像感知哈希.
半自动化清洗包括:
- 图像级别的清洗: 利用预先训练的植物/非植物图像分类器对图像文件进行打分, 非植物图像应该有较低的得分; 利用前一阶段的植物分类器对图像文件 (每个文件都有一个预标类别) 进行预测, 取预标类别的概率值为得分, 不属于原预标类别的图像应该有较低的得分. 可以设置阈值, 滤除很低得分的文件; 另外利用得分对图像文件进行重命名, 并在资源管理器选择按文件名排序, 以便于后续手工清洗掉非植物图像和不是预标类别的图像.
- 类级别的清洗: 参考 数据集清洗方法几则.
手工清洗: 人工判断文件夹下图像是否属于文件夹名所标称的物种, 这需要相关的植物学专业知识, 是最耗时且枯燥的环节, 但也凭此认识了不少的植物.
数据现状
笔者把收集的数据集分为了正式集和候选集. 正式集每个分类单元的图像数基本上都在 100 张以上, 主要用来做训练. 候选集中的物种的图像比较少, 待图像量上来后会加入到正式集中, 或者后面直接用来做植物检索的底库.
- 20210413: 正式集有 1,320 个分类单元, 460,352 张图像.
- 20210609: 正式集有 1,630 个分类单元, 586,557 张图像.
- 20210718: 正式集有 2,002 个分类单元, 749,763 张图像.
- 20210905: 正式集有 2,759 个分类单元, 996,690 张图像; 候选集有 3,784 个分类单元, 80,893 张图像.
- 20211024: 正式集有 4,066 个分类单元, 1,451,934 张图像; 候选集有 3,248 个分类单元, 69,396 张图像.
模型训练
受算力和显存所限 (仅有一块 GTX 1660), 骨干网络选用轻量级的网络 (如 ResNet18, MobileNetV2_1.0), 损失函数为 softmax 交叉熵. 优化器为 SGD, 使用了 L2 正则化, 标签平滑正则化, 余弦退火学习率衰减策略和学习率预热. 这个方案比较保守, 待笔者有了更多的算力, 会尝试一些新的方案, 如细粒度图像检索 (FGIR), 度量学习, 自监督学习, 模型蒸馏等.
当前的模型直接输出各类的置信度, 也可以将模型改造成特征提取器, 用自己的植物图像来构造底库, 这样可以用图像检索的方式来进行植物识别, 可扩展性更高.
- 20210413: 发布的模型训练了 30 个 epoch, 在 GTX 1660 上大概用了 39 个小时, 在 23,026 张图像的测试集上, Top1 准确率为 0.940.
- 20210609: 发布的模型训练了 30 个 epoch, 在 GTX 1660 上大概用了两天多, 在 29,313 张图像的测试集上, Top1 准确率为 0.924.
- 20210718: 发布的模型训练了 30+ 个 epoch, 在 GTX 1660 上大概用了三天多, 在 74,961 张图像的测试集上, Top1 准确率为 0.900.
- 20210905: 发布的模型训练了 30 个 epoch, 在 GTX 1660 上大概用了三天多, 在 99,676 张图像的测试集上, Top1 准确率为 0.890, Top5 准确率为 0.970.
- 20211024: 发布的模型训练了 30 个 epoch, 在 GTX 1660 上大概用了两天多, 在 145,168 张图像的测试集上, Top1 准确率为 0.848, Top5 准确率为 0.959.
版权声明
自由转载-非商用-非衍生-保持署名 (创意共享3.0许可证)